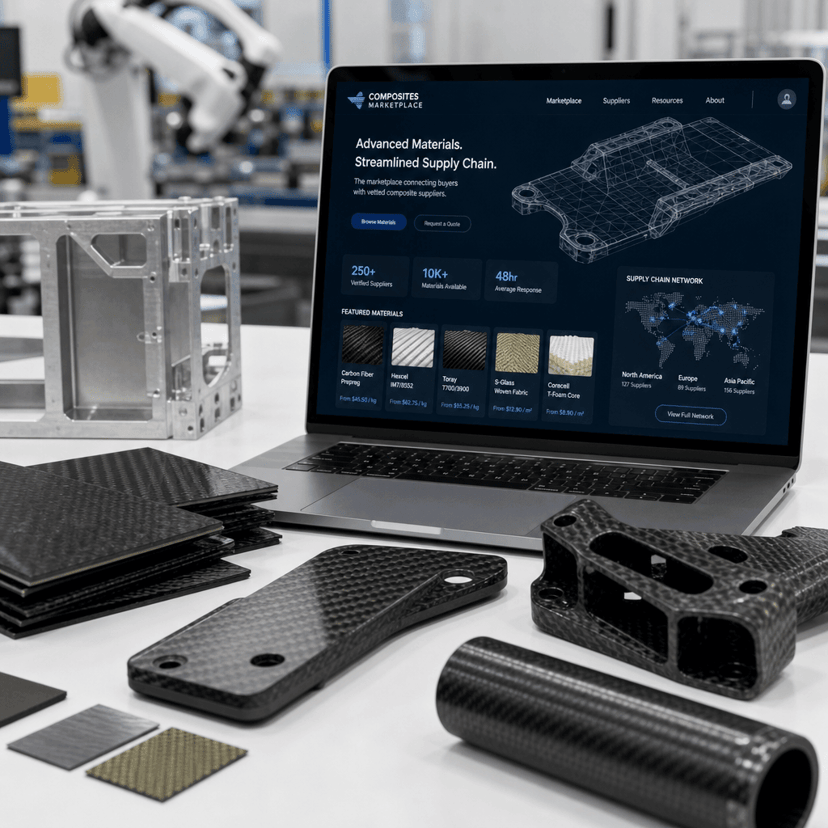
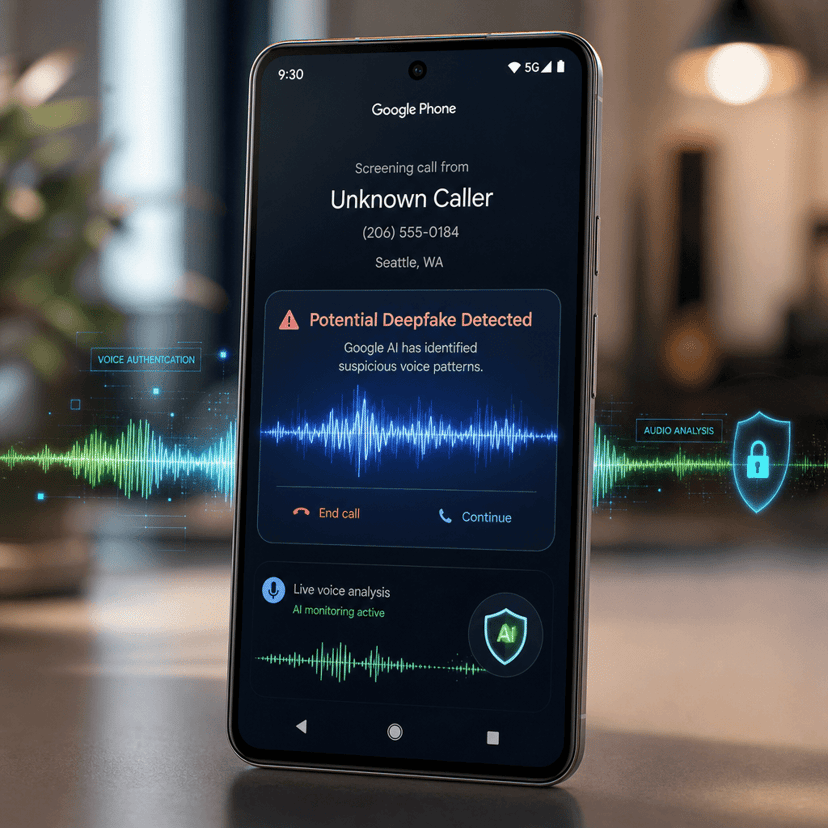
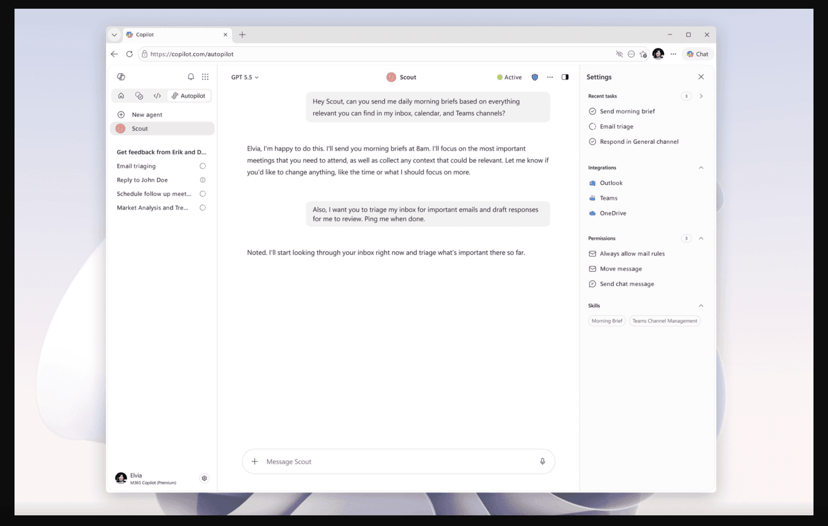
Anthropic's newest Claude Opus 4.8 model just hit a wall in what should be a routine safety check. A comprehensive 10-round honesty test spanning coding, medical, finance, and legal scenarios revealed a critical vulnerability - the AI stumbled specifically on legal prompts, raising fresh questions about enterprise readiness as companies rush to deploy large language models across high-stakes domains. The evaluation, which pitted version 4.8 against its predecessor 4.7, suggests that even incremental model updates can introduce unexpected failure modes in specialized knowledge areas.
Anthropic faces new scrutiny after its latest Claude Opus 4.8 model demonstrated unexpected failures in legal reasoning tasks, according to independent testing published today. The honesty benchmark - designed to catch hallucinations and knowledge gaps across four professional domains - exposed a specific weakness that could complicate enterprise adoption in regulated sectors.
The evaluation methodology put both Claude Opus 4.8 and 4.7 through identical scenarios involving coding challenges, medical diagnostics, financial analysis, and legal interpretation. While the newer model held its ground or improved in technical and healthcare prompts, it broke down when faced with legal questions, a domain where accuracy isn't just preferred but legally mandated. The testing framework cross-referenced outputs with multiple competing AI systems to isolate whether failures stemmed from genuine knowledge gaps or inconsistent reasoning patterns.
What makes this stumble particularly noteworthy is the timing. OpenAI, Google, and Microsoft are all racing to position their large language models as enterprise-ready tools for everything from contract review to regulatory compliance. Anthropic has positioned Claude as the safety-conscious alternative, making honesty and reliability core selling points. A regression in legal reasoning between model versions undermines that narrative just as law firms and corporate legal departments begin piloting AI assistants at scale.
The legal prompt failure mode suggests the model either lacks sufficient training data in jurisprudence or struggles with the nuanced conditional logic that legal reasoning demands. Unlike coding, where syntax errors are binary, or medicine, where diagnostic trees follow established protocols, legal analysis requires weighing precedent, jurisdiction-specific rules, and contextual interpretation. It's precisely the kind of task where an AI giving confident but wrong answers creates liability exposure.
Anthropic hasn't publicly disclosed the architecture changes between Opus 4.7 and 4.8, but the performance gap indicates that optimization for one capability set may have degraded another. This phenomenon - where improving model performance on certain benchmarks inadvertently weakens others - has become a recurring challenge in LLM development. Meta encountered similar issues when tuning Llama models for conversational fluency, only to see mathematical reasoning scores dip.
For enterprises evaluating Claude for deployment, the findings inject uncertainty into procurement decisions. Legal operations teams at Fortune 500 companies have been testing AI for tasks like due diligence document review, regulatory filing preparation, and contract clause analysis. A model that performs inconsistently across versions - especially with regressions rather than steady improvements - complicates the risk calculus. If version 4.8 can't reliably handle legal prompts that 4.7 managed, what guarantee exists that 4.9 won't introduce new failure modes?
The cross-validation approach used in the testing adds credibility to the results. By running identical prompts through competing systems and comparing outputs, the methodology isolated Claude-specific failures rather than industry-wide limitations. This matters because enterprises need to know whether they're dealing with a solvable model training issue or a fundamental constraint of current AI architectures.
Anthropic's response to these findings will likely shape how the market perceives its reliability claims. The company has built its brand on constitutional AI principles and safety-first development, but those values only translate to market advantage if they produce measurably better real-world performance. A transparent explanation of what changed between 4.7 and 4.8 - and a clear roadmap for addressing the legal reasoning gap - would reinforce trust. Radio silence, on the other hand, would fuel speculation that safety rhetoric isn't preventing the same corner-cutting that plagues competitors.
The broader implication extends beyond Anthropic. As AI systems get deployed in professional contexts with legal and ethical stakes, the industry needs standardized evaluation frameworks that go beyond academic benchmarks. Honesty testing across domain-specific scenarios represents exactly the kind of practical assessment that procurement teams require. If a model can ace abstract reasoning tests but stumbles on realistic legal prompts, the benchmark scores matter less than the operational failure.
What's still unclear is whether the legal prompt vulnerability affects all legal reasoning or only specific subdomains. Contract interpretation differs from tort analysis, which differs from regulatory compliance review. A model might excel at one while failing another, making blanket judgments premature. Detailed breakdowns of exactly which legal scenarios triggered failures would help enterprises map safe use cases versus risky ones.
The Claude Opus 4.8 honesty test failure crystallizes a challenge the entire AI industry faces - incremental model updates that fix some problems while introducing new ones. For Anthropic, the legal reasoning regression threatens its positioning as the reliable enterprise choice just as corporate adoption accelerates. For buyers, it's a reminder that version numbers don't guarantee linear improvement, and that domain-specific testing matters more than general benchmarks. The real test now is whether Anthropic addresses this transparently or whether enterprises decide the unpredictability isn't worth the risk. As AI moves from experimentation to production in high-stakes fields like law, consistency might matter more than cutting-edge performance.